這篇是去年因某些因素,未在科技新報發表的過期文章,就乾脆放在blog做功德了。
雖然微軟和Meta (臉書) 是這票雲端巨頭之中,在這條自研晶片之路上腳步稍晚者,明顯落後於領頭的AWS、Google甚至阿里巴巴,但直起直追的速度卻頗為可觀,在2024年的HotChips,揭露其最新AI晶片的全貌,而我們也有充分的理由相信,雲端巨頭們競相將HotChips作為成果發表會與隔空較勁的舞台,將會是世人習以為常的精彩畫面。
為執行OpenAI模型而量身訂做的微軟Maia 100 AI加速器

Maia 100是微軟第一代自研AI加速器,用於Azure OpenAI服務,提供REST API存取OpenAI的強大語言模型,包括o1-preview、o1-mini、GPT-4o、GPT-4o mini、GPT-4 Turbo with Vision、GPT-4、GPT-3.5-Turbo和Embeddings模型系列。 微軟也開宗明義自研晶片的理由:軟硬體垂直整合以最佳化效能與降低成本。
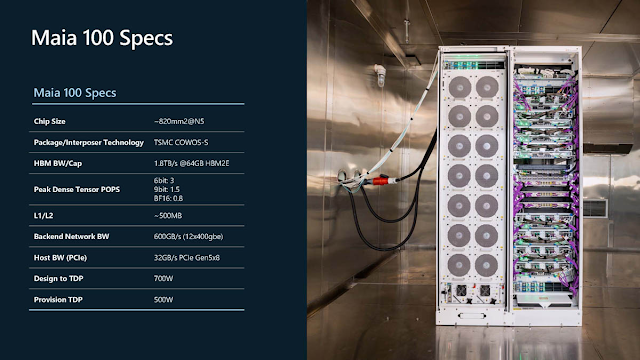
這頁是Maia 100的關鍵規格,在不同資料精度時有相異的運算效能比例,使用台積電N5 (5奈米) 製程,是一顆晶粒面積約略820平方公釐的大晶片 (1050億電晶體),標準設計功耗700W (實際佈署時約500W),並透過2.5D封裝技術CoWoS-S連接容量64GB的HBM2e記憶體 (理論頻寬1.8TB/s),這意味著微軟無須 (或無法) 跟Nvidia和AMD等競爭者搶奪HBM3貨源。值得注意的是,藉由理論頻寬32GB/s的PCIe Gen5 x8與主機相連的Maia 100,內建了總計500MB容量的L1/L2 SRAM記憶體,與12埠400GbE (等同於英特爾Gaudi 3的24埠200GbE)。「網路」在大型AI運算叢集的重要性,在此不言可喻。
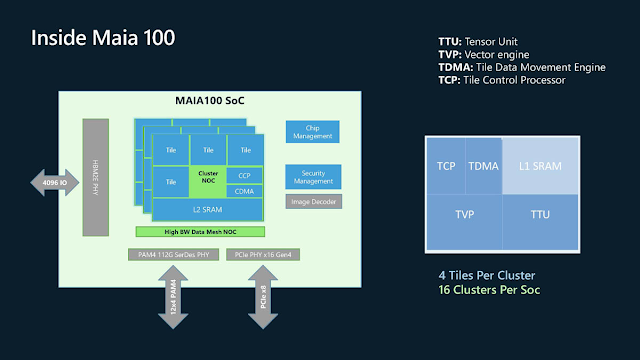
Maia 100的運算模塊 (Tile) 由TTU (張量單元)、TVP (向量引擎)、TDMA (資料搬移引擎) 與TCP (控制處理器) 所構成,四個Tile組成一個叢集,Maia 100的16個叢集總計64個Tile。

Maia 100的張量單元支援廣泛的資料類型,包括9位元和6位元運算,向量引擎則對應常見的FP32與BF16,兼顧推論和訓練的需求。資料搬移引擎可將被分片 (Sharding) 的張量移動到不同的計算單元,而硬體層級的同步機制 (Hardware Semaphore) 則用在多個處理單元之間的同步和互斥管理,優化異步編程 (Async Programming) 的性能表現。

Maia 100內部連結16個叢集的晶片內網路 (NOC, Network-On-Chip) 拓樸,資料壓縮傳輸、更小的資料格式與可經由軟體控制的L1/L2記憶體,有助於資料儲存與搬移。
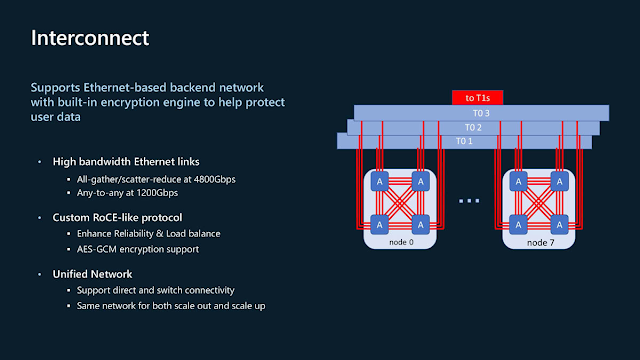
微軟身為超級乙太網路聯盟 (UEC) 的推動者之一,選擇乙太網路做為互連架構基礎也是合情合理。微軟在Maia 100放入自訂的「類RoCE」協定強化網路的可靠度與負載平衡,與保護用戶資料的加密引擎。
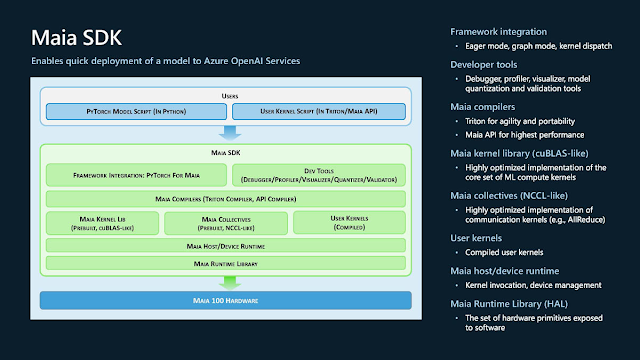
Maia 100的軟體開發套件 (SDK) 全貌,目的不外乎快速將AI模型佈署在Azure OpenAI服務。但筆者也不得不好奇,如同DirectX的演進軌跡,在未來,微軟是否考慮將所有的AI環境都統一在DirectML之下。
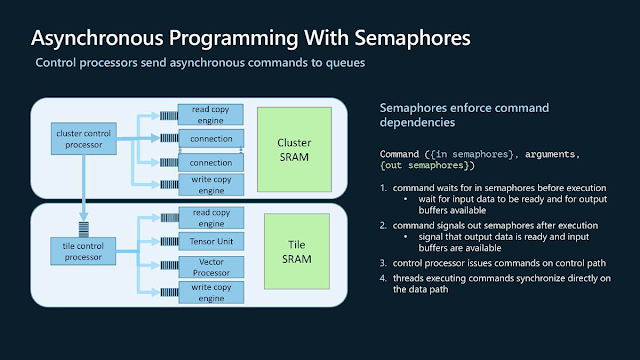
Maia 100的非同步程式設計模型。對於多核系統的資源利用率和異步作業的效率,基於硬體的同步機制 (Hardware Semaphore) 至關重要,因為可減少上下文切換 (Context Switch) 的開銷與因忙碌等待 (Busy-Wating) 而浪費的處理器資源。

Triton是一種開源語言和編譯器,用於編寫高效的機器學習計算核心,提高了開發人員編寫GPU程式碼的效率,但Triton語言與硬體無關,足以適用於Maia 100等非GPU硬體架構。開發者可透過Triton或Maia API進行程式設計,而Maia API理所當然的提供了更多的底層控制權。
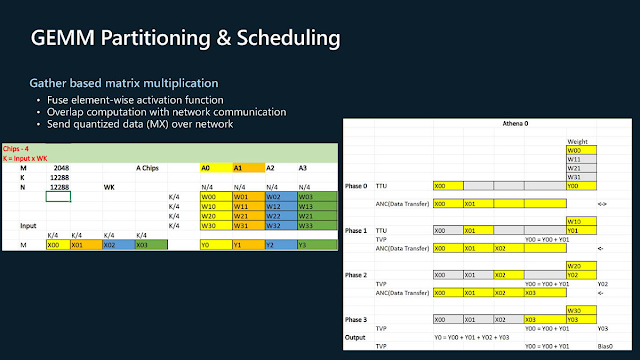
通用矩陣乘法 (GEMM) 的運算單元分區與調度案例。
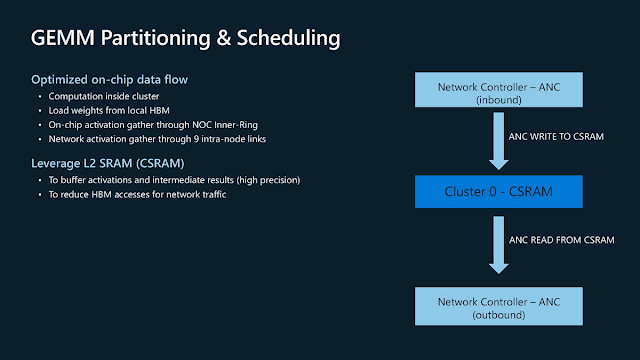
無論晶片內的網路還是對L2 SRAM的使用方式,都設法盡其所能的塞滿運算單元。

微軟宣稱將使用PyTorch開發的模型佈署在Maia 100會有「開箱即用 (Out-Of-Box)」的體驗,只要修改ㄧ行程式碼即可。
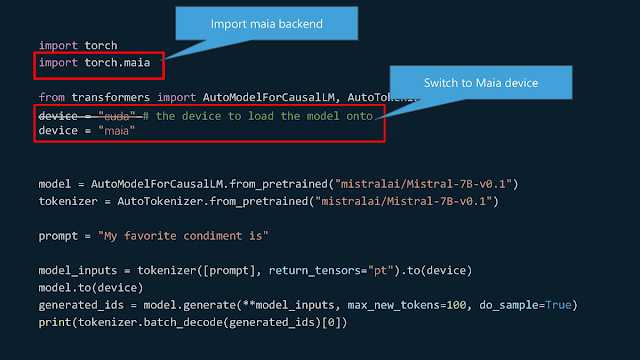
這頁特別的有意義:載入Maia的後端,從Nvidia的CUDA換成微軟的Maia。

Maia可用的通訊函式庫,有別於PyTorch內建的Gloo和Nccl,Mccl是微軟為Maia自訂的擴展。

Maia SDK的開發工具所提供的功能,這裡強烈暗示了微軟過去使用過Nvidia和AMD (ROCm) 的系統管理界面 (SMI),不外乎Nvidia的歷代旗艦GPU與在一年前引進微軟資料中心的AMD MI300X。
支撐臉書推薦系統的第二代自研AI加速器
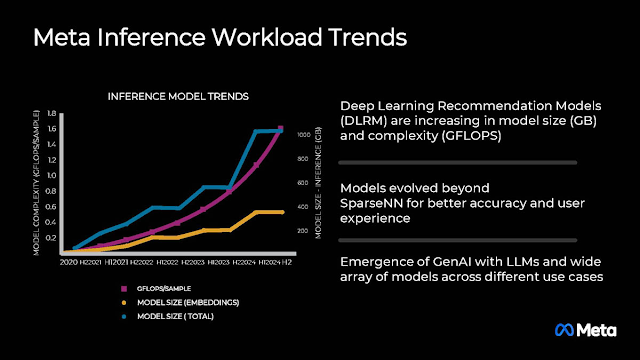
Meta在人工智慧已耕耘多年,在這其中的一大關鍵應用就是決定臉書要推播那些內容給用戶的「推薦引擎」,這也是自研MTIA (Meta Training and Inference Accelerator) 的初衷:旨在高效地服務於為用戶提供高品質推薦的排名和推薦模型。Meta透過建立Triton-MTIA編譯器後端為MTIA硬體產生高效能程式碼。
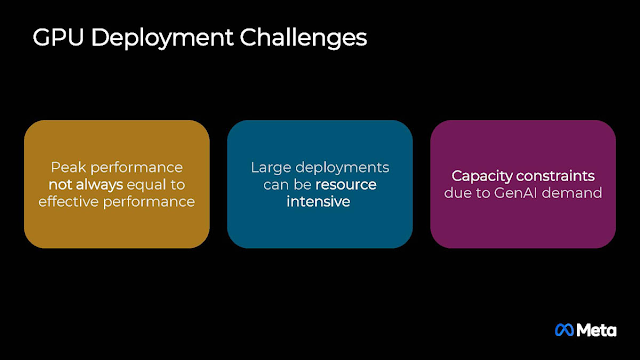
Meta表示使用GPU執行推薦引擎存在許多挑戰,包括峰值效能不等同於實際的表現、大規模部份極度耗費資源、與記憶體容量的限制。

新一代的MTIA v2將克服這些困難,不僅提昇每總體持有成本和瓦數的效能、有效的運行多種Meta的服務,並改進開發效率以因應大規模的佈署。

MTIA v2的成就均匯集於此。歸功於稀疏計算管線相關的架構改進,MTIA v2顯著拉抬密集運算(MTIA v1的3.5倍)和2x稀疏運算(7倍)。動態整數量化可在INT8大幅減少資料量的情況提供接近FP32的精確度。PyTorch的Eagar Mode (動態計算圖模式) 根據代碼逐行執行動態構建並立即執行對應的操作,加速計算工作的配發與更換。TBE (Table Batched Embedding) 是用於高效處理表格資料中嵌入向量的技術,常見於推薦系統,將大規模稀疏數據 (如用戶特徵、商品特徵等) 轉化為稠密向量,以便進一步進行模型訓練或推理,對此MTIA v2比前代快了兩到三倍。

和微軟Maia 100相同,MTIA v2以台積電5奈米製程製造,時脈1.35GHz,晶粒面積421平方公釐,標準設計功耗90W,通用矩陣乘法 (GEMM) 的理論效能分別是354 TOPS (INT8) 與 177 TOPS (FP16)。因為這是為了推薦引擎的「推論」所設計的,所以記憶體採用理論頻寬「僅」204.8GB/s的128GB LPDDR5-6400,而不是昂貴的HBM。
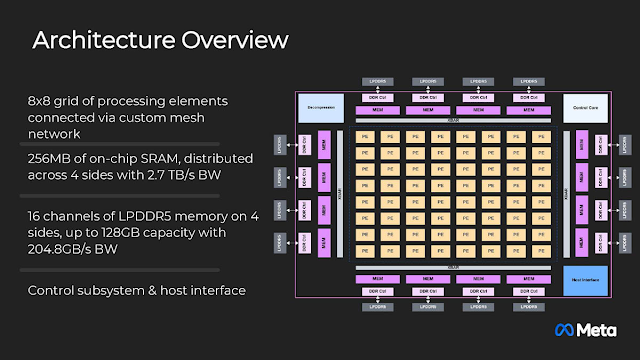
除了16通道的LPDDR5-6400記憶體,還有用於8x8計算網格的256GB內建SRAM,這是前代的兩倍。
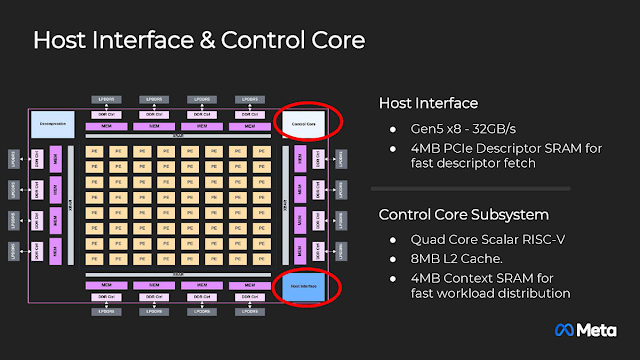
MTIA v2藉由PCIe Gen5 x8連結主機 (Host),具有專用的4MB SRAM存放PCIe的工作描述器以加速擷取從主機派發的運算工作。有趣的是,MTIA v2的控制用處理器是四核心的純量RISC-V CPU,有8MB L2快取與用來加快工作分配的4MB本文 (Context) SRAM。

連結64個運算單元 (PE, Processing Element) 的晶片內網路 (NOC) 2.76TB/s理論頻寬是MTIA v1的3.4倍。
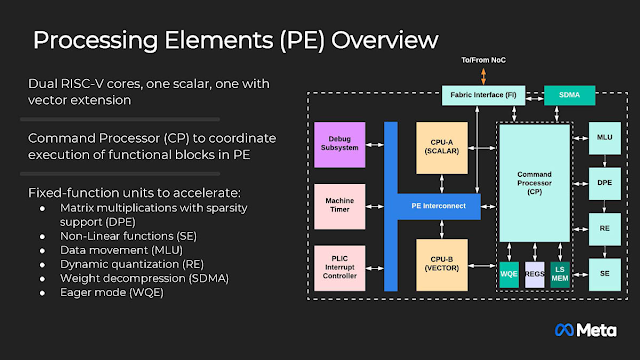
每個PE都是雙核的RISC-V核心,一個專職純量,一個負責向量,搭配各式各樣的功能單元,並由命令處理器 (CP, Command Processor) 去協調內部的運作。
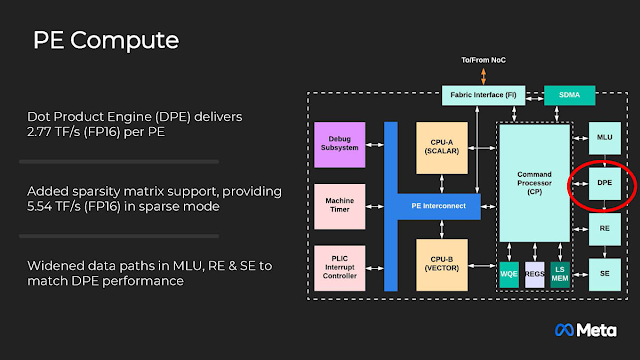
向量內積 (Dot Product) 是兩個同維度向量的乘積和,在深度學習領域堪稱最基本也最常用的數學操作之一,尤其在大規模矩陣運算的場景,PE內部配置專用的硬體單元,並對應2x稀疏率。
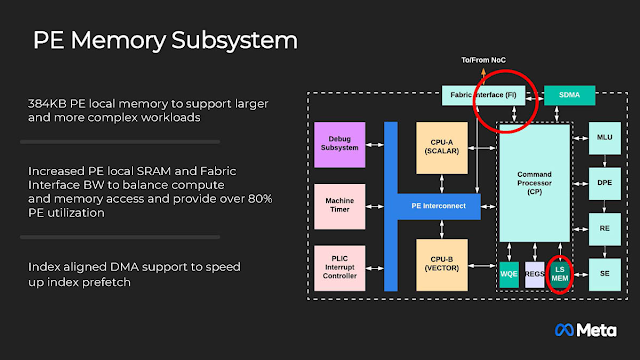
PE的本地端記憶體為384kB,Meta表示PE內部的充沛傳輸頻寬對保持運算單元利用率 (超過80%) 非常重要。
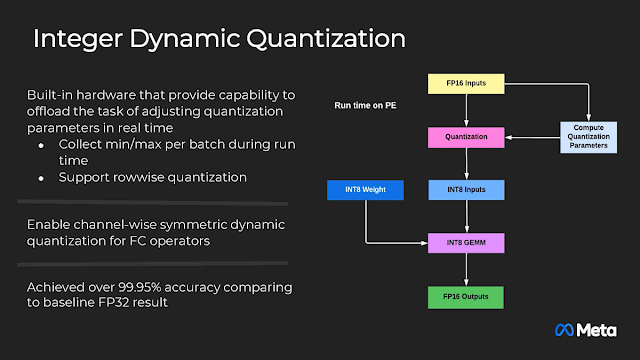
在硬體中運行的高精度整數動態量化引擎,INT8可達到FP32的99.95%準確度。
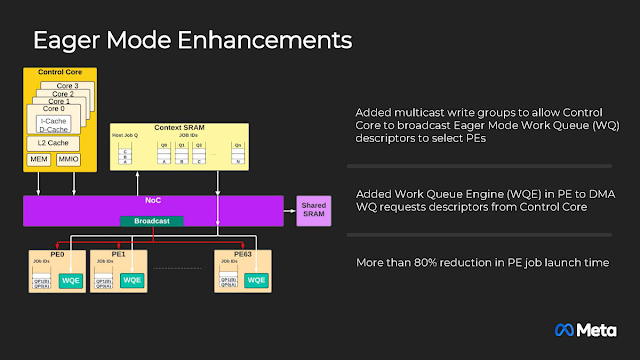
PyTorch的Eager Mode用於縮短作業啟動時間,並提供更快的回應速度。
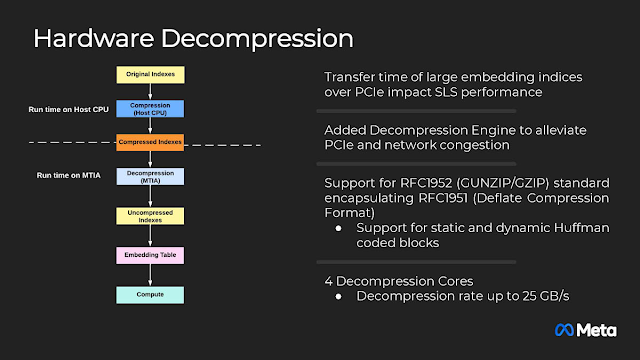
硬體解壓縮引擎用來減少資料傳輸量,拉高實際的有效頻寬,四個解壓縮引擎核心的速度是25GB/s。
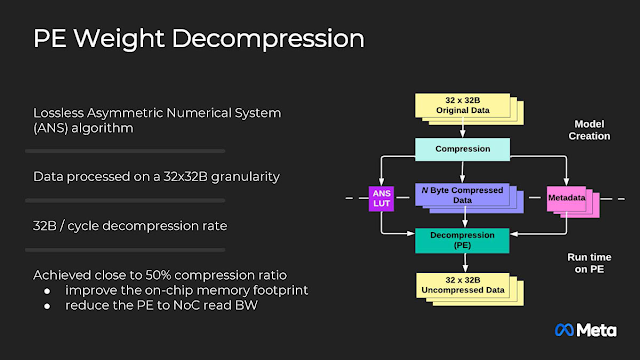
在深度學習模型中,特別是大型模型,權重矩陣可能非常龐大,導致高昂的儲存需求和計算開銷。為了解決這一問題,模型壓縮技術被廣泛應用,以減少權重矩陣的存儲大小。Weight Decompression (權重解壓縮) 是一種用於神經網路中處理壓縮模型權重的技術,目的是在壓縮和解壓之間找到性能和效率的平衡,將壓縮儲存的權重恢復成可用於計算的格式 (還原為近似的原始矩陣或結構),以便進行推理或訓練。MTIA v2的權重壓縮率接近50%,減少晶片內記憶體的消耗量與晶片內網路讀取資料的所需頻寬,提昇20%傳輸效率。

推薦系統中的表格資料通常以嵌入層 (Embedding) 的形式處理,這些嵌入層需要為每個類別特徵生成對應的向量。隨著資料規模的增長 (如以數百萬計的用戶和商品等),嵌入層的維度變得非常大,這時就需要高效的方法進行批量 (Batch) 處理,TBE就是在這種需求下誕生的技術,而擁有專用硬體加持的MTIA v2在此的效能是前代的兩到三倍,可謂飛躍性的進步。

每張加速器模組有兩個MTIA v2晶片,標準設計功耗220W,每顆MTIA v2都由獨立的PCIe Gen5 x8連結主機,總計是64GB/s的對外理論傳輸頻寬,與256GB容量LPDDR5記憶體。
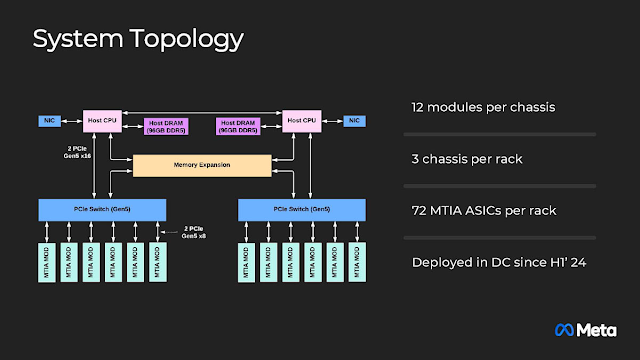
MTIA v2的機箱系統架構圖,裡面有12個加速器模組,每個機架的三個機箱有72個MITA v2,從2024年上半年開始實際佈署。從圖中可判斷Meta保留了經由CXL擴充記憶體的升級彈性。論耗電量,每個機架的72個MTIA v2大約用掉16kW,6個CPU則可能低於3kW,換言之,無須動用供電40kW以上等級的機架,降低機房門檻。同場加映,Nvidia GB200 NVL72是驚人的120kW,相當於近300戶家庭的用電量。
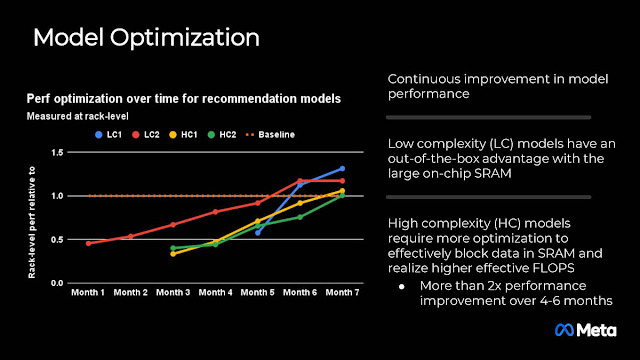
在Meta評估的四個關鍵模型中,MTIA v2的性能比第一代晶片增加了3倍。在平台層面,與第一代MTIA系統相比,憑藉2倍的設備數量和強大的2路CPU,實現6倍的模型服務吞吐量和1.5倍的每瓦效能提升。為了實現這一目標,Meta宣稱「在優化核心、編譯器、執行環境和主機服務堆疊方面取得了重大進展」。隨著開發者生態系的成熟,優化模型的時間正在縮短,但未來改進效率的空間更大,在短短4至6個月就有兩倍的效能增長。
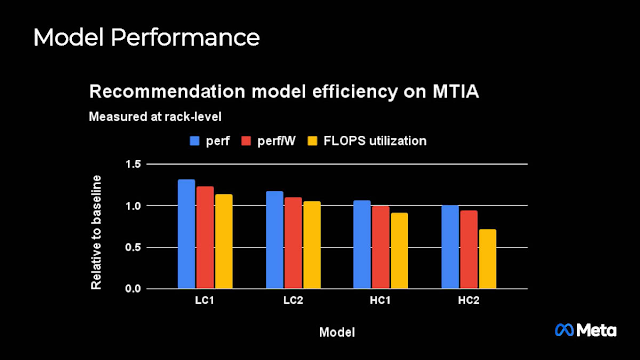
MTIA處理作為Meta產品組件的低複雜性 (LC) 和高複雜性 (HC) 排名和建議模型,但從這裡面看不出比較的「基準線」究竟是什麼。
請不要忘記雲端巨頭自研晶片背後的「影武者」們
無獨有偶的,目前「地球上最大AI算力軍火商」Nvidia也在2024年初,決意進軍ASIC市場,和博通、Marvell、與AI相關的台灣ASIC業者包括世芯 (AIchip,AWS先前的主要合作夥伴,英特爾Gaudi 3是其近期成果)、創意 (Global Unichip,上述微軟Maia 100為其代表作)、聯發科 (MediaTek)、晶心科 (Andes) 等正面競爭,而身處內憂外患的英特爾,亦著手替AWS客製化Xeon 6處理器,AMD更為微軟Azure做了MI300C。畢竟比的就是設計能力,「服務雲端巨頭」將是所有獨立處理器廠商難以逃避的挑戰,話說回來,以這方面的能量著稱的x86雙雄,假以時日,或許有機會藉此殺出一條血路也說不定,假若他們還有這個餘力的話。
延伸閱讀:
Hot Chips 2023》當 ARM 伺服器 CPU 核心 IP 也 Chiplet 化:Arm Neoverse CSS N2
ARM 狂潮,x86 黄昏將至?(一)x86 處理器的資料中心、伺服器霸權起點何在
ARM 狂潮,x86 黄昏將至?(二)雲端巨頭自研晶片究竟可以省多少?
ARM 狂潮,x86 黄昏將至?(三)為何自研晶片的門檻越來越低?
ARM 狂潮,x86 黄昏將至?(四)暫居優勢的 x86 雙雄該如何自力救濟?
Hot Chips 2024》活在 x86 雙雄「核戰」與雲端巨頭自研晶片陰影下的 Arm 伺服器 CPU:核心數激增的 AmpereOne
HotChips 2024》聚焦於 AI 的乙太網路互連架構與來自 AMD 的遺珠之憾
HotChips 2024 》降低 GPU 集群算力閒置率的 Enfabrica
最低寫入延遲,特斯拉 Dojo 超級電腦的獨家 TTPoE 傳輸層協定
AMD 為微軟 Azure 客製化 EPYC CPU,具 HBM3 可能是 MI300C
Hot Chips 2024》矽光子先驅卻迷途,英特爾的技術進度與市場困境
HotChips 2024 》矽光子與運算晶片整合的「影武者」,一窺博通資料中心技術
沒有留言:
張貼留言